As the title says, is this possible with pyRevit?
We have Ideate Software and when I tried to use this to do a find/replace, it got rid of my numbered list like this:
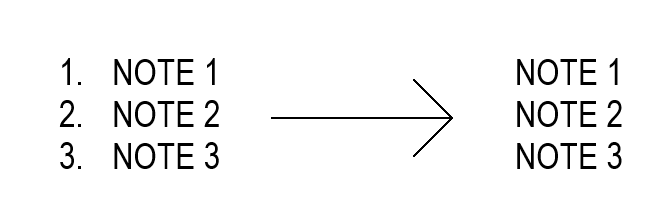
Revit does have a find/replace but it applies it either per active view or project wide, not by selected sheets (which is how I need to go about due to project phase setup).
Has anyone attempted this with pyRevit? I have had not luck. It was yielding the same results as with Ideate Software. I was able to come up with this so far. If anyone has any suggestions or solutions, I would appreciate that information. Thanks.
# -*- coding: utf-8 -*-
# pyRevit | IronPython 2.7 | Revit 2023–2025
__title__ = "Edit Text"
__doc__ = "Select Text Notes (all, pre-selected, pick, or entire project) and apply Find/Replace, Prefix, or Suffix edits with live preview and filtering."
import clr, os
clr.AddReference("RevitAPI")
clr.AddReference("PresentationFramework")
clr.AddReference("PresentationCore")
clr.AddReference("System.Xaml")
from Autodesk.Revit.DB import *
from Autodesk.Revit.UI.Selection import ObjectType, ISelectionFilter
from pyrevit import revit, forms, script
from System.Windows.Markup import XamlReader
from System.IO import FileStream, FileMode
from System.Windows import Window
from System.Windows.Media import Brushes
from System.Windows import FontWeights
from System.Windows.Controls import Label
from System.Windows import TextWrapping, Thickness
# ---------------- Context ---------------- #
doc = revit.doc
uidoc = revit.uidoc
if not doc or not uidoc:
forms.alert("No active Revit document.", title="Error")
script.exit()
# ---------------- Selection Filter ---------------- #
class TextNoteSelectionFilter(ISelectionFilter):
def AllowElement(self, elem):
return isinstance(elem, TextNote)
def AllowReference(self, ref, point):
return False
# ---------------- UI Window ---------------- #
class LiveTextEditWindow(Window):
def __init__(self, original_texts):
# --- Load XAML layout ---
xaml_path = os.path.join(os.path.dirname(__file__), "EditText_ui.xaml")
fs = FileStream(xaml_path, FileMode.Open)
content = XamlReader.Load(fs)
fs.Close()
# Window setup
self.Title = "Live Preview Text Edit"
self.Width = 1500
self.Height = 550
from System.Windows import WindowStartupLocation
self.WindowStartupLocation = WindowStartupLocation.CenterScreen
self.Content = content
self.was_confirmed = False
# Data
self.original_texts = original_texts
self.filtered_texts = list(original_texts)
# --- Bind XAML Controls ---
self.tb_filter = content.FindName("tb_filter")
self.tb_mode = content.FindName("tb_mode")
self.tb_find = content.FindName("tb_find")
self.tb_replace = content.FindName("tb_replace")
self.old_list = content.FindName("old_list")
self.new_list = content.FindName("new_list")
self.ok = content.FindName("ok")
self.cancel = content.FindName("cancel")
self.status_label = content.FindName("status_label")
# --- Events ---
self.tb_filter.TextChanged += self.filter_texts
self.tb_find.TextChanged += self.update_preview
self.tb_replace.TextChanged += self.update_preview
self.tb_mode.SelectionChanged += self.update_preview
self.ok.Click += self.on_ok
self.cancel.Click += self.on_cancel
self.old_list.SelectionChanged += self.sync_selection_old
self.new_list.SelectionChanged += self.sync_selection_new
# Default selection
if self.tb_mode.SelectedIndex < 0:
self.tb_mode.SelectedIndex = 0
# Auto-focus and initialize after load
def on_loaded(sender, args):
self.tb_filter.Focus()
self.filter_texts(None, None)
self.new_list.SizeChanged += self.update_preview
self.old_list.SizeChanged += self.update_preview
self.Loaded += on_loaded
# ---------------- Filtering Logic ---------------- #
def filter_texts(self, sender, args):
term = (self.tb_filter.Text or "").lower().strip()
if not term:
self.filtered_texts = list(self.original_texts)
else:
self.filtered_texts = [t for t in self.original_texts if term in t.lower()]
self.update_preview(None, None)
# ---------------- Preview Logic ---------------- #
# ---------------- Preview Logic ---------------- #
def update_preview(self, sender, args):
try:
if not self.filtered_texts:
self.status_label.Content = "⚠️ No text notes found or filtered out."
self.old_list.Items.Clear()
self.new_list.Items.Clear()
return
find = self.tb_find.Text or ""
replace = self.tb_replace.Text or ""
filter_term = (self.tb_filter.Text or "").strip()
mode_item = self.tb_mode.SelectedItem
mode = mode_item.Content.ToString() if mode_item else "Find/Replace"
from System.Windows.Controls import TextBlock
from System.Windows.Documents import Run
self.old_list.Items.Clear()
self.new_list.Items.Clear()
changed_count = 0
for name in self.filtered_texts:
tb_old = TextBlock()
tb_old.Text = name
tb_old.TextWrapping = TextWrapping.Wrap
tb_old.TextTrimming = 0
tb_old.Margin = Thickness(2, 0, 2, 4)
#tb_old.Width = self.old_list.ActualWidth - 25 if self.old_list.ActualWidth > 25 else 400
padding_margin = 35 # accounts for scrollbar + internal margins
tb_old.Width = max(100, self.old_list.ActualWidth - padding_margin)
#tb.Width = max(100, self.new_list.ActualWidth - padding_margin)
self.old_list.Items.Add(tb_old)
new = name
if mode == "Find/Replace" and find:
new = name.replace(find, replace)
elif mode == "Prefix":
new = replace + name
elif mode == "Suffix":
new = name + replace
# --- Build Highlighted TextBlock ---
# --- Build Highlighted TextBlock (with wrapping) ---
tb = TextBlock()
tb.TextWrapping = TextWrapping.Wrap
tb.TextTrimming = 0 # Disable ellipsis truncation
tb.Margin = Thickness(2, 0, 2, 4)
#tb.Width = self.new_list.ActualWidth - 25 if self.new_list.ActualWidth > 25 else 400
padding_margin = 35 # accounts for scrollbar + internal margins
#tb_old.Width = max(100, self.old_list.ActualWidth - padding_margin)
tb.Width = max(100, self.new_list.ActualWidth - padding_margin)
if filter_term and filter_term.lower() in new.lower():
lower_new = new.lower()
lower_term = filter_term.lower()
start = 0
while True:
idx = lower_new.find(lower_term, start)
if idx == -1:
tb.Inlines.Add(Run(new[start:]))
break
# Add normal part before match
if idx > start:
tb.Inlines.Add(Run(new[start:idx]))
# Add matched part highlighted
match = Run(new[idx:idx + len(filter_term)])
match.Foreground = Brushes.Blue
match.FontWeight = FontWeights.Bold
tb.Inlines.Add(match)
start = idx + len(filter_term)
else:
tb.Inlines.Add(Run(new))
# --- Apply change color for modified lines ---
if new != name:
changed_count += 1
tb.Foreground = Brushes.Blue
tb.FontWeight = FontWeights.Bold
self.new_list.Items.Add(tb)
self.status_label.Content = "{} / {} visible | {} will change".format(
len(self.filtered_texts), len(self.original_texts), changed_count
)
except Exception as e:
print("Preview error:", e)
# ---------------- Selection Sync ---------------- #
def sync_selection_old(self, sender, args):
idx = self.old_list.SelectedIndex
if idx >= 0 and idx < self.new_list.Items.Count:
self.new_list.SelectedIndex = idx
def sync_selection_new(self, sender, args):
idx = self.new_list.SelectedIndex
if idx >= 0 and idx < self.old_list.Items.Count:
self.old_list.SelectedIndex = idx
# ---------------- Buttons ---------------- #
def on_ok(self, sender, args):
self.was_confirmed = True
self.Close()
def on_cancel(self, sender, args):
self.was_confirmed = False
self.Close()
# ---------------- Helpers ---------------- #
def get_textnotes_all():
"""Get all TextNotes belonging to the active view (handles Sheets, Drafting, Legends, etc.)."""
active_view_id = doc.ActiveView.Id
try:
# Primary collector scoped to active view
collector = FilteredElementCollector(doc, active_view_id).OfClass(TextNote)
notes = list(collector)
if notes:
return notes
# Fallback: global collector filtered by OwnerViewId
all_notes = FilteredElementCollector(doc).OfClass(TextNote).WhereElementIsNotElementType()
return [n for n in all_notes if n.OwnerViewId == active_view_id]
except Exception as e:
print("Collector error:", e)
return []
def get_textnotes_selected():
"""Let user manually pick TextNotes only."""
try:
refs = uidoc.Selection.PickObjects(ObjectType.Element, TextNoteSelectionFilter(), "Select Text Notes")
return [doc.GetElement(r.ElementId) for r in refs if isinstance(doc.GetElement(r.ElementId), TextNote)]
except:
return []
def get_textnotes_preselected():
"""Use currently pre-selected TextNotes in Revit."""
sel_ids = uidoc.Selection.GetElementIds()
if not sel_ids:
return []
return [doc.GetElement(i) for i in sel_ids if isinstance(doc.GetElement(i), TextNote)]
def get_textnotes_all_project():
"""Collect all TextNotes in the entire project."""
return list(FilteredElementCollector(doc).OfClass(TextNote).WhereElementIsNotElementType())
def get_textnotes_from_selected_sheets():
"""Collect all TextNotes from user-selected Sheets, including both sheet-based and view-based notes."""
# --- Collect all sheets ---
sheets = list(FilteredElementCollector(doc)
.OfCategory(BuiltInCategory.OST_Sheets)
.WhereElementIsNotElementType())
if not sheets:
forms.alert("No sheets found in project.", title="Error")
return []
# --- Build display list ---
sheet_dict = {}
display_list = []
for s in sheets:
try:
label = "{} - {}".format(s.SheetNumber, s.Name)
sheet_dict[label] = s
display_list.append(label)
except:
pass
selected_labels = forms.SelectFromList.show(
sorted(display_list),
multiselect=True,
title="Select Sheets to Collect Text Notes"
)
if not selected_labels:
return []
selected_sheets = [sheet_dict[l] for l in selected_labels]
selected_sheet_ids = [s.Id for s in selected_sheets]
# ----------------------------------------------------------------------
# PART 1 — Collect all view IDs placed on selected sheets
# ----------------------------------------------------------------------
view_ids = []
for s in selected_sheets:
vports = FilteredElementCollector(doc, s.Id).OfClass(Viewport).ToElements()
for vp in vports:
view_ids.append(vp.ViewId)
# ----------------------------------------------------------------------
# PART 2 — Collect all TextNotes directly placed on selected sheets
# ----------------------------------------------------------------------
sheet_textnotes = []
for sid in selected_sheet_ids:
try:
notes_on_sheet = FilteredElementCollector(doc, sid).OfClass(TextNote).ToElements()
sheet_textnotes.extend(notes_on_sheet)
except:
pass
# ----------------------------------------------------------------------
# PART 3 — Collect all TextNotes from the views placed on those sheets
# (uses your original reliable method)
# ----------------------------------------------------------------------
view_textnotes = []
for vid in view_ids:
try:
notes_in_view = FilteredElementCollector(doc, vid).OfClass(TextNote).ToElements()
view_textnotes.extend(notes_in_view)
except:
pass
# ----------------------------------------------------------------------
# Combine results (deduplicate by ElementId)
# ----------------------------------------------------------------------
unique_ids = set()
combined = []
for n in sheet_textnotes + view_textnotes:
if n.Id not in unique_ids:
unique_ids.add(n.Id)
combined.append(n)
return combined
# ---------------- MAIN ---------------- #
choice = forms.SelectFromList.show(
[
"Select All (Active View)",
"Pre-selected",
"User Selection",
"Select All (Selected Sheets)",
"Select All in Project"
],
title="Select which Text Notes to edit:",
multiselect=False
)
if choice == "Cancel" or not choice:
script.exit()
elif choice == "Select All (Active View)":
notes = get_textnotes_all()
elif choice == "Pre-selected":
notes = get_textnotes_preselected()
elif choice == "User Selection":
notes = get_textnotes_selected()
elif choice == "Select All (Selected Sheets)":
notes = get_textnotes_from_selected_sheets()
elif choice == "Select All in Project":
notes = get_textnotes_all_project()
else:
script.exit()
if not notes:
forms.alert("No text notes found for that selection.", title="Error")
script.exit()
# --- Filter out text notes that are part of a group ---
grouped_notes = []
clean_notes = []
for n in notes:
try:
if hasattr(n, "GroupId") and n.GroupId != ElementId.InvalidElementId:
grp = doc.GetElement(n.GroupId)
if isinstance(grp, Group):
grouped_notes.append(n)
continue
if hasattr(n, "SuperComponent") and n.SuperComponent and isinstance(n.SuperComponent, Group):
grouped_notes.append(n)
continue
clean_notes.append(n)
except:
clean_notes.append(n)
if grouped_notes:
forms.alert(
"⚠️ {} Text Notes belong to groups and will be skipped from editing.".format(len(grouped_notes)),
title="Grouped Text Notes Skipped"
)
notes = clean_notes
original = [n.Text for n in notes]
dialog = LiveTextEditWindow(original)
dialog.ShowDialog()
if not dialog.was_confirmed:
script.exit()
mode_item = dialog.tb_mode.SelectedItem
mode = mode_item.Content.ToString() if mode_item else "Find/Replace"
find = dialog.tb_find.Text or ""
replace = dialog.tb_replace.Text or ""
filtered_texts = dialog.filtered_texts
with revit.Transaction("Edit Text Notes"):
for n in notes:
if n.Text not in filtered_texts:
continue
txt = n.Text
if mode == "Find/Replace" and find:
txt = txt.replace(find, replace)
elif mode == "Prefix":
txt = replace + txt
elif mode == "Suffix":
txt = txt + replace
n.Text = txt
<Grid xmlns="http://schemas.microsoft.com/winfx/2006/xaml/presentation"
xmlns:x="http://schemas.microsoft.com/winfx/2006/xaml"
Background="White"
Margin="10">
<Grid.RowDefinitions>
<RowDefinition Height="*" />
<RowDefinition Height="30" />
</Grid.RowDefinitions>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="200" />
<ColumnDefinition Width="*" />
</Grid.ColumnDefinitions>
<!-- LEFT PANEL -->
<StackPanel Grid.Column="0" Margin="5">
<!-- Filter -->
<Label Content="Filter (contains):" Foreground="Blue" />
<TextBox x:Name="tb_filter" Width="180" Margin="0,0,0,8" />
<!-- Mode -->
<Label Content="Mode" Foreground="Blue" />
<ListBox x:Name="tb_mode" Height="70" Margin="0,0,0,8">
<ListBoxItem Content="Find/Replace" />
<ListBoxItem Content="Prefix" />
<ListBoxItem Content="Suffix" />
</ListBox>
<!-- Find -->
<Label Content="Find" Foreground="Blue" />
<TextBox x:Name="tb_find" Width="180" Margin="0,0,0,8" />
<!-- Replace / Prefix / Suffix -->
<Label Content="Replace / Prefix / Suffix" Foreground="Blue" />
<TextBox x:Name="tb_replace" Width="180" Margin="0,0,0,8" />
<Label Height="20" />
<!-- Buttons -->
<StackPanel Orientation="Horizontal" HorizontalAlignment="Left">
<Button x:Name="ok" Content="Apply" Width="80" Margin="2" Foreground="Blue" />
<Button x:Name="cancel" Content="Cancel" Width="80" Margin="2" Foreground="Blue" />
</StackPanel>
</StackPanel>
<!-- RIGHT PANEL -->
<Grid Grid.Column="1">
<Grid.RowDefinitions>
<RowDefinition Height="30" />
<RowDefinition Height="*" />
</Grid.RowDefinitions>
<!-- Column Headers -->
<Grid>
<Grid.ColumnDefinitions>
<ColumnDefinition Width="*" />
<ColumnDefinition Width="*" />
</Grid.ColumnDefinitions>
<Label Content="Original" Foreground="Blue" Grid.Column="0" />
<Label Content="Preview" Foreground="Blue" Grid.Column="1" />
</Grid>
<!-- Lists -->
<Grid Grid.Row="1">
<Grid.ColumnDefinitions>
<ColumnDefinition Width="*" />
<ColumnDefinition Width="*" />
</Grid.ColumnDefinitions>
<ListBox x:Name="old_list"
Grid.Column="0"
MinWidth="200"
HorizontalContentAlignment="Stretch"
ScrollViewer.HorizontalScrollBarVisibility="Disabled"
ScrollViewer.VerticalScrollBarVisibility="Auto" />
<ListBox x:Name="new_list"
Grid.Column="1"
MinWidth="200"
HorizontalContentAlignment="Stretch"
ScrollViewer.HorizontalScrollBarVisibility="Disabled"
ScrollViewer.VerticalScrollBarVisibility="Auto" />
</Grid>
</Grid>
<!-- STATUS BAR -->
<Label x:Name="status_label" Grid.Row="1" Grid.ColumnSpan="2"
Foreground="Blue" Content="" />
</Grid>